 |
Foundation Models for Robotics |
 |
Interactive Robot Learning |
| Human-AI/Robot Interaction |
Foundation Models for Robotics

We show how to adapt FMs to handle complex robotics tasks, such as using keypoint prediction to enable fine-grained semantic manipulation in KITE.
In recent years, we have observed incredible and fascinating capabilities of foundation models (FMs), large-scale models pre-trained on a broad range of data (e.g., GPT-4 or PaLM-E). Our lab has seen surprising results of these FMs on their own: for example, they can serve as general sequence models, extrapolating state sequences to complete low-level motions in a completely zero-shot manner. However, these FMs are sometimes not readily applicable to robotics tasks straight out of the box: in ILIAD, we are interested in developing methods to leverage and adapt FMs to handle the complex, fine-grained, and multi-modal tasks we encounter in robotics.

We show that LLMs can surprisingly complete abstract sequences out-of-the-box, such as assisting a human in completing a table sweeping task.
Pretraining Large Models

Voltron learns language-driven representations from videos with associated captions, enabling strong performance on a diverse set of robotics tasks requiring both low-level spatial features and high-level semantics.
At the most basic level, we are interested in understanding what underlying techniques and methodological advances are needed towards building stronger FMs and generative models for robotics tasks. For example, many robotics tasks (e.g., grasp affordance or language instruction following) require combining both low-level spatial features with high-level semantics, but FMs purely trained on video datasets fail to capture both. To this end, we have released Voltron, a framework for language-driven representation learning from human videos with accompanying captions. Likewise, other successful generative modeling approaches such as diffusion models are unsuccessful for many robotics tasks due to extremely high latency – up to 30 seconds for a simple push task! We designed a method to effectively parallelize the sampling procedure, allowing us to harness the power of diffusion models without significantly sacrificing latency.
Semantic Manipulation via Multimodal Inputs
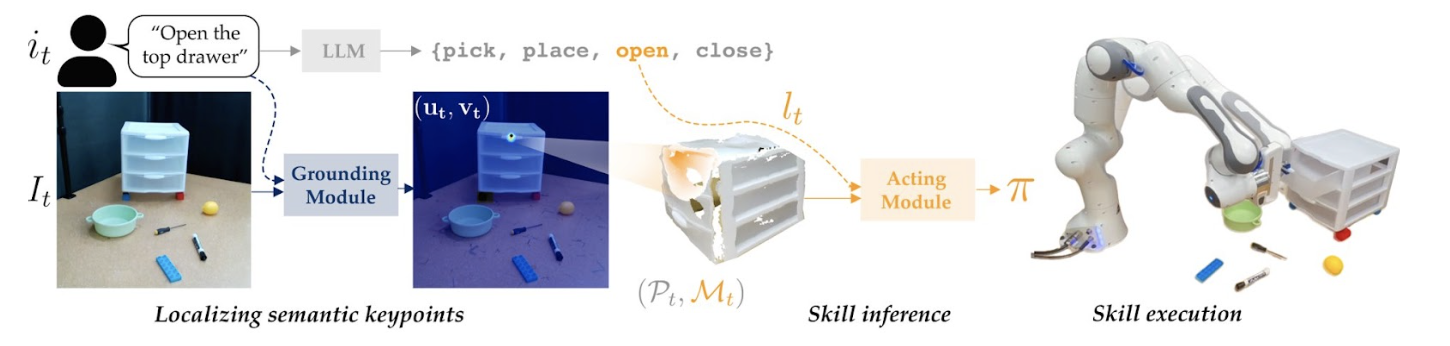
KITE combines a keypoint-prediction grounding module with an LLM to more effectively handle semantic manipulation.
Robotics tasks are inherently multi-modal, and can require handling inputs such as images, language, and even human gestures. No single FM can handle this kind of multi-modality, but do there exist clever ways we can adapt FMs to enable more natural interfaces between humans and robots? For example, current vision language models (VLMs) fail to capture within-object semantics (e.g., picking up a stuffed-elephant from its ear), so we demonstrate how keypoint prediction can help create a data-efficient way of simultaneously handling both high-level semantics and high-precision tasks enabling semantic manipulation. Additionally, we show how to combine human gestures with LLMs to generate a sequence of robot actions that combine both verbal (e.g., “give me that tool”) and non-verbal (pointing to a tool) modes for providing feedback.
Reward Design
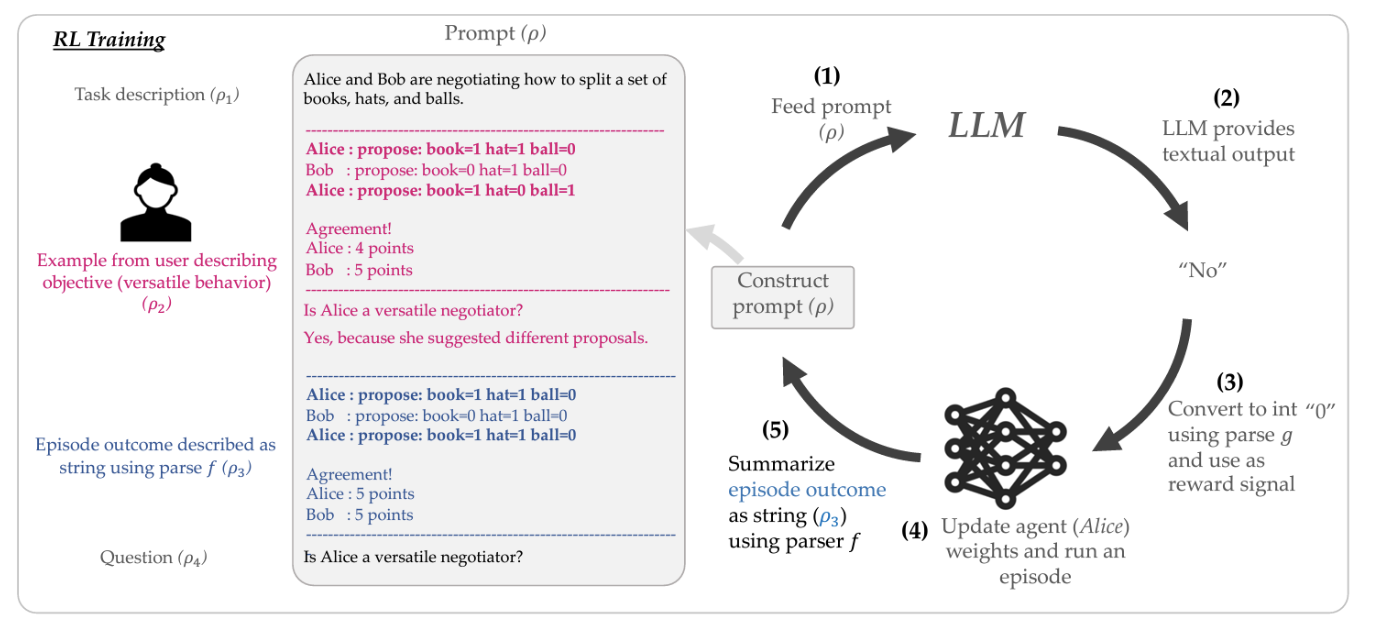
We create an iterative reward design process that allows users to either express objectives or provide examples to an LLM in natural language.
Another application of FMs we are interested in is their ability to aid with reward design, or helping humans better express challenging social contexts for AI agents to consider. For example, we have shown how to leverage the rich social-reasoning information present in pre-trained LLMs like GPT-3 to help humans more efficiently design rewards for complex social situations like negotiation, as well help robots complete tasks in a socially-aware way (e.g., not disassembling a puzzle while cleaning a housing). Other ways of leveraging LLMs for reward design that we are interested include rregularizing AI agent policies with human preferences expressed in natural language, and setting parameters of reward functions for low-level robotic tasks.
Social and Commonsense Reasoning

We combine LLMs with active perception from VLMs to generate socially-acceptable action plans (e.g., check if the banana is peeled before throwing it away).
Finally, we are interested in how FMs can help provide social semantic reasoning necessary for successful task completion. For example, we recently showed how to combine both an LLM and a VLM to help “ground” a robots’ actions plan not only in its physical context, but also in a social sense by using the LLM to suggest which action plans are more socially-acceptable than others. Likewise, we showed how to adapt human demonstration trajectories in order to leverage LLM’s rich semantic understanding of spatial “corrections” (e.g., faster is the opposite of slower) for a natural language feedback generation system. In addition to social reasoning, we have also recently developed the PhysObjects dataset for fine-tuning VLMs to enable stronger physical reasoning capabilities (e.g. material, fragility).