 |
Foundation Models for Robotics |
 |
Interactive Robot Learning |
| Human-AI/Robot Interaction |
Human-AI/Robot Interaction
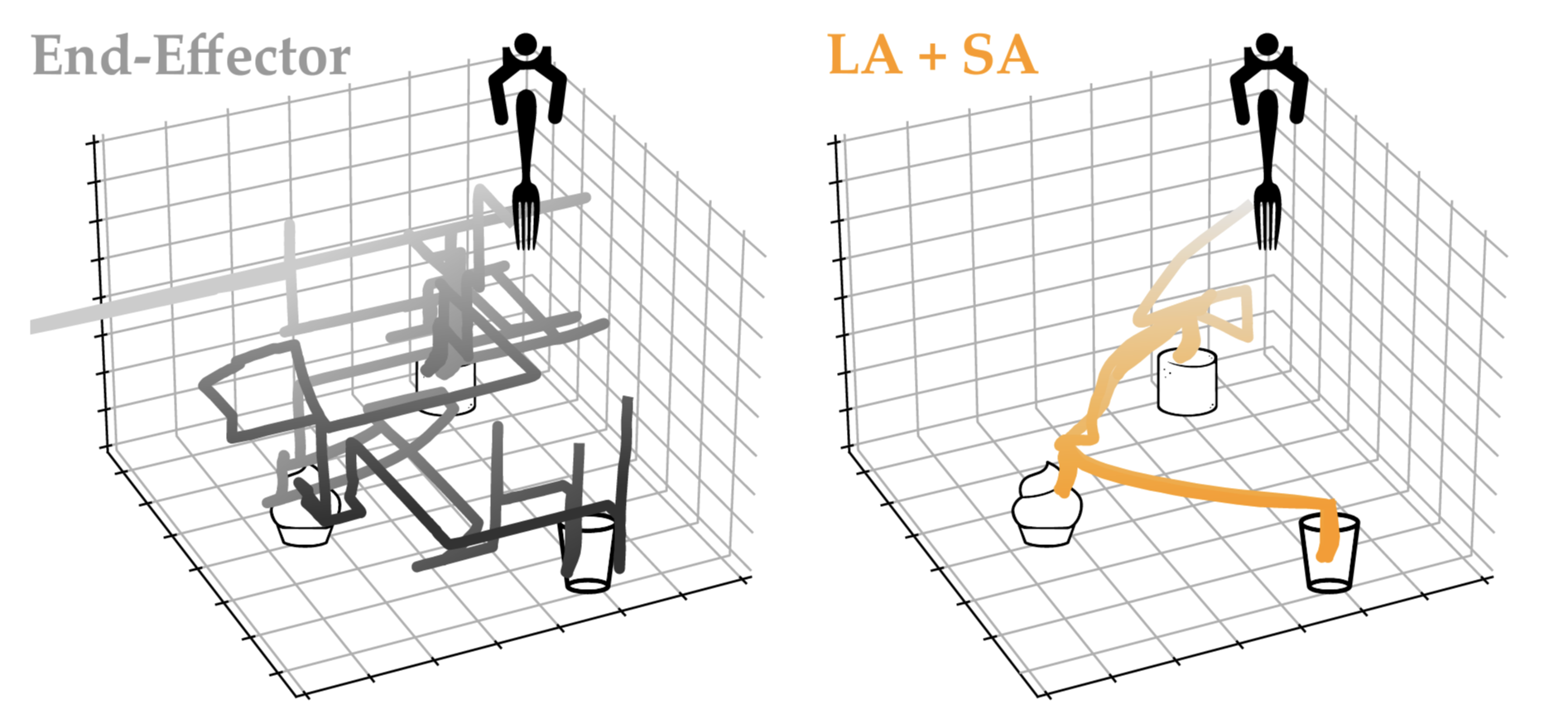
Average trajectories of two human subject study participants with physical disabilities are quicker and more accurate with our approach of learning latent actions and shared autonomy than standard end-effector control on an assistive feeding task.
Situations where humans interact with AI agents are increasingly ubiquitous, from drivers “handing-off” control to semi-autonomous vehicles to medical professionals learning to operate surgical robots. We are interested in formalizing these interactions and developing methods that ensure they are more reliable and seamless. To this end, we develop novel ways to help AI agents better collaborate with humans to complete a task, reason about complex multi-modal tasks such as food acquisition, and teach human students to improve their own performance in physical control tasks.
Shared Autonomy
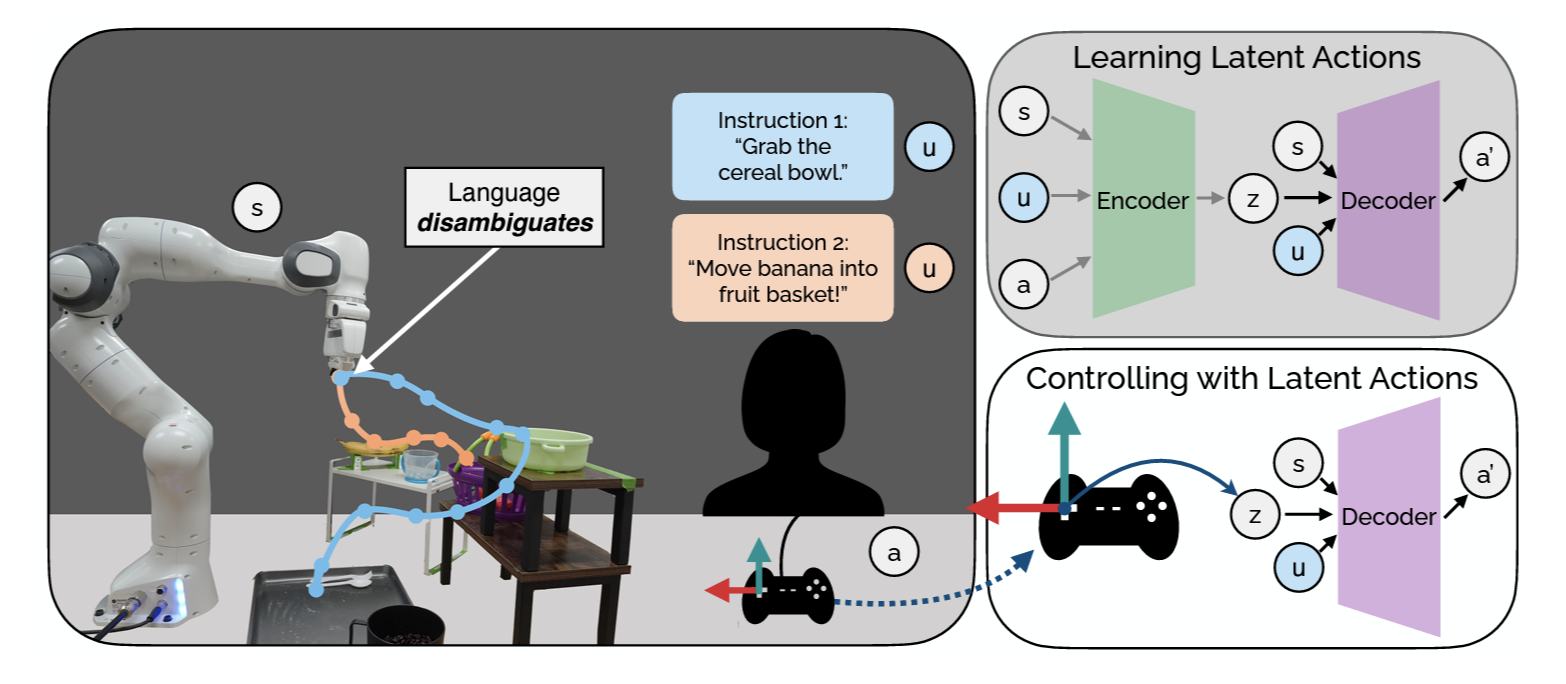
LILA allows users to flexibly provide natural language to modulate the control space, where language utterances map to different learned latent actions users can operate with.
For almost one million American adults living with physical disabilities, picking up a bite or food or pouring a glass of water presents a significant challenge. Wheelchair-mounted robotic arms – and other physically assistive devices – hold the promise of increasing user autonomy, reducing reliance on caregivers and improving quality of life. However, the very dexterity that makes these robotic assistants useful also makes them hard for humans to control. Our lab has explored ways to make such shared autonomous settings easier for humans by, for example, leverage latent representations of actions to enable intuitive control of the robots, and more precise manipulation for food acquisition and transfer. More recently, we have developed LILA: Language-Informed Latent Actions and LILAC: Language-Informed Latent Actions with Corrections, to incorporate language instructions and corrections as more flexible and natural input to enable more intuitive teleoperation.
Food Acquisition and Transfer

![]()

Left: We use visual and haptic information to adaptively choose skewering primitives for food acquisition. Middle: We use depth perception and force-reactive controllers to design a system for transferring food to a human’s mouth that is safe and comfortable. Right: We learn a high-level action selection policy for long-horizon food acquisition by using simulated latent plate dynamics.
Performing nuanced low-level control for complex manipulation tasks such as food acquisition and transfer would greatly benefit from perception that effectively captures the physical world. We explore leveraging multiple available perception modalities to enable effective reasoning for performing such food manipulation tasks, such as by using visual and haptic information to rapidly and reactively plan skewering motions for food acquisition, using depth perception and force-reactive controllers to optimize for the safety and comfort of food transfer to a human, and leveraging simulation to learn hierarchical policies for long-horizon food manipulation.
Teaching Humans
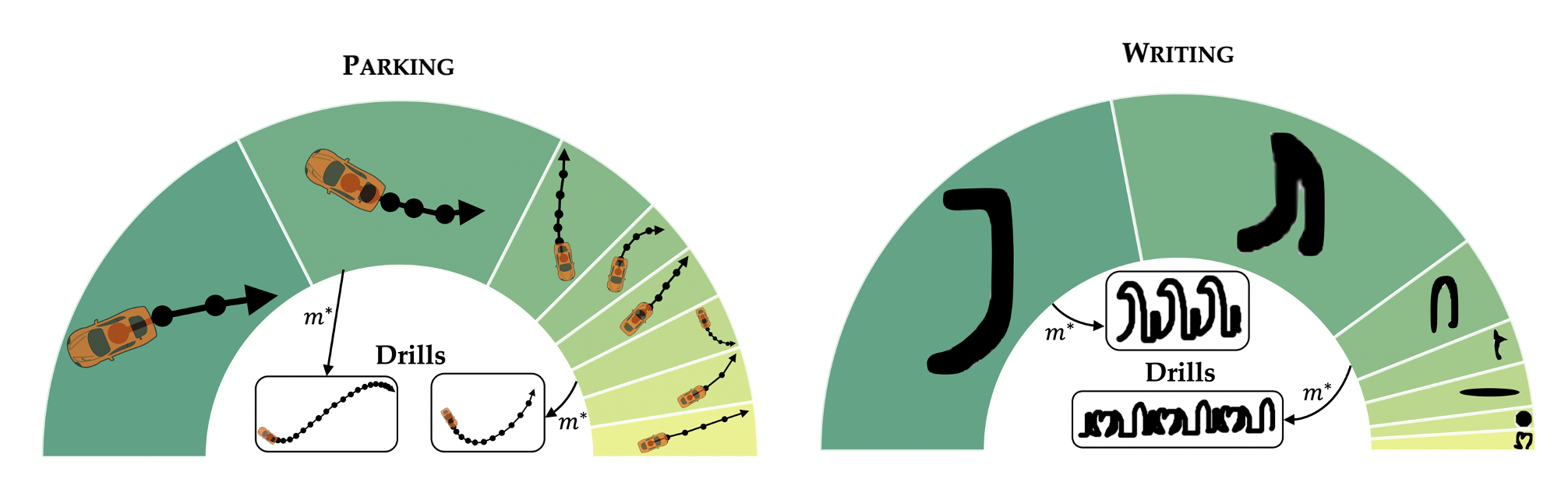
We leverage skill-discovery algorithms to decompose motor control tasks into teachable skills, allowing us to create curricula that lead to improved human performance.
While shared autonomous systems help human users achieve a task, such as picking up food or driving to the grocery store, we are interested in ways we can further help teach humans. For hobbies like sports or playing the piano, or safety-critical tasks such as robot-assisted surgery where we may always want a human-in-the-loop, how can we design AI agents that can help humans improve at a task? We have tried to formalize this setting with AI Assisted Teaching of Motor Control Tasks to Humans, where we explore how to leverage skill-discovery algorithms and methods from RL to design curricula for human students to practice, as well as developed methods for providing appropriate feedback to humans providing demonstrations for robot data collection. We have also recently explored leveraging LLMs to generate personalized feedback to students, based on their action trajectories, for different control tasks such as driving a vehicle or running.