 |
Foundation Models for Robotics |
 |
Interactive Robot Learning |
| Human-AI/Robot Interaction |
Interactive Robot Learning
Data Quality in Imitation Learning

HYDRA improves the sample efficiency for learning real world long-horizon tasks by modifying robot action spaces to reduce online distribution shift.
In robotics, scaling up data collection for imitation learning is often challenging, and our test settings are constantly shifting from the training data. Therefore, if we want robots to learn new tasks scalably, we need to be more sample efficient with both learning methods and the type of data we collect. We study the interaction between models and data sources for learning manipulation tasks in robotics, such as by using hybrid action spaces to reduce online distribution shift, and studying and curating diverse datasets for imitation learning.
Learning from Suboptimal Data

To learn policies that can generalize to diverse tasks and settings, we need algorithms that can leverage broad, suboptimal forms of data and adapt quickly to new information. Our goal is to develop learning techniques that can take advantage of the broadest set of data to teach robots real world tasks. For example, we have studied obtaining policy improvement when learning from suboptimal offline data using only supervised learning, which enables learning policies that outperform dataset behavior as desired in offline reinforcement learning, but with better stability when learning from high-dimensional data. Unstructured human play is another form of suboptimal data that can be more scalable to collect than demonstrations. We have explored improving methods that learn from play data by taking an object centric approach to structuring behavior for modeling object affordances, which can improve policy learning for manipulation.
Cross-Embodiment Learning



PolyBot enables data transfer across different robot embodiments.
Reusing large robotic datasets to scale up robot learning will likely entail training policies on data originally collected for different robotic platforms. Transferring behavior across different platforms poses many challenges due to the wide variation in factors such as control schemes and morphologies across platforms. We investigate ways to better facilitate such transfer, such as by aligning observations, action spaces, and internal representations across different platforms.
Active Learning of Human Preferences
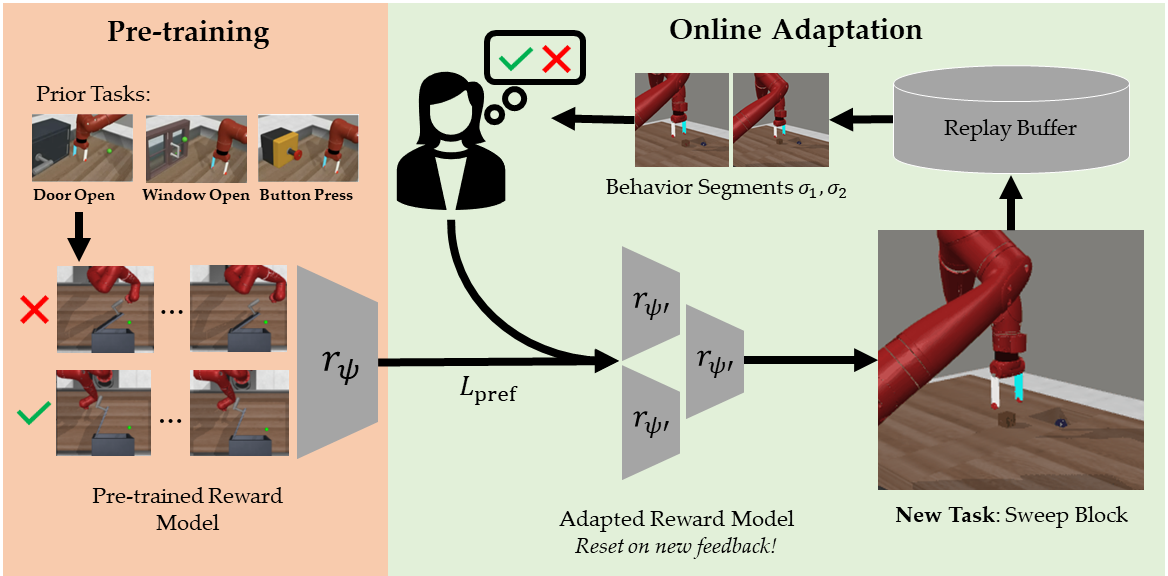
Pre-training reward models via meta learning enables fast adaptation of rewards to new tasks.
Preference-based reward learning has become an increasingly popular method for aligning AI systems with human values, such as with language modeling. However, scaling up human preferences to the amounts needed for tasks requiring complex sequential decision making, such as in robotics, remains challenging. To this end, we have worked on methods that improve the sample complexity of preference-based learning, such as through active learning to elicit more informative feedback, meta-learning on prior task data, or eliminating the need for a reward function entirely.
Leveraging Structure: Bimanual Manipulation



By leveraging structure in bimanual manipulation tasks, we can efficiently learn policies for tasks like jacket zipping that generalize across different jackets.
Bimanual robotics open the door to more complex manipulation capabilities, but this also entails a new challenge: how should two arms coordinate with each other? We explore methods that exploit physical patterns and principles to define coordination paradigms in a low-data regime, such as stabilizing food items during food acquisition without interfering with the acquisition behavior. More generally, we can use a stabilizing arm to simplify an environment by keeping parts of it unchanged, to facilitate tasks such as zipping jackets or cutting vegetables.